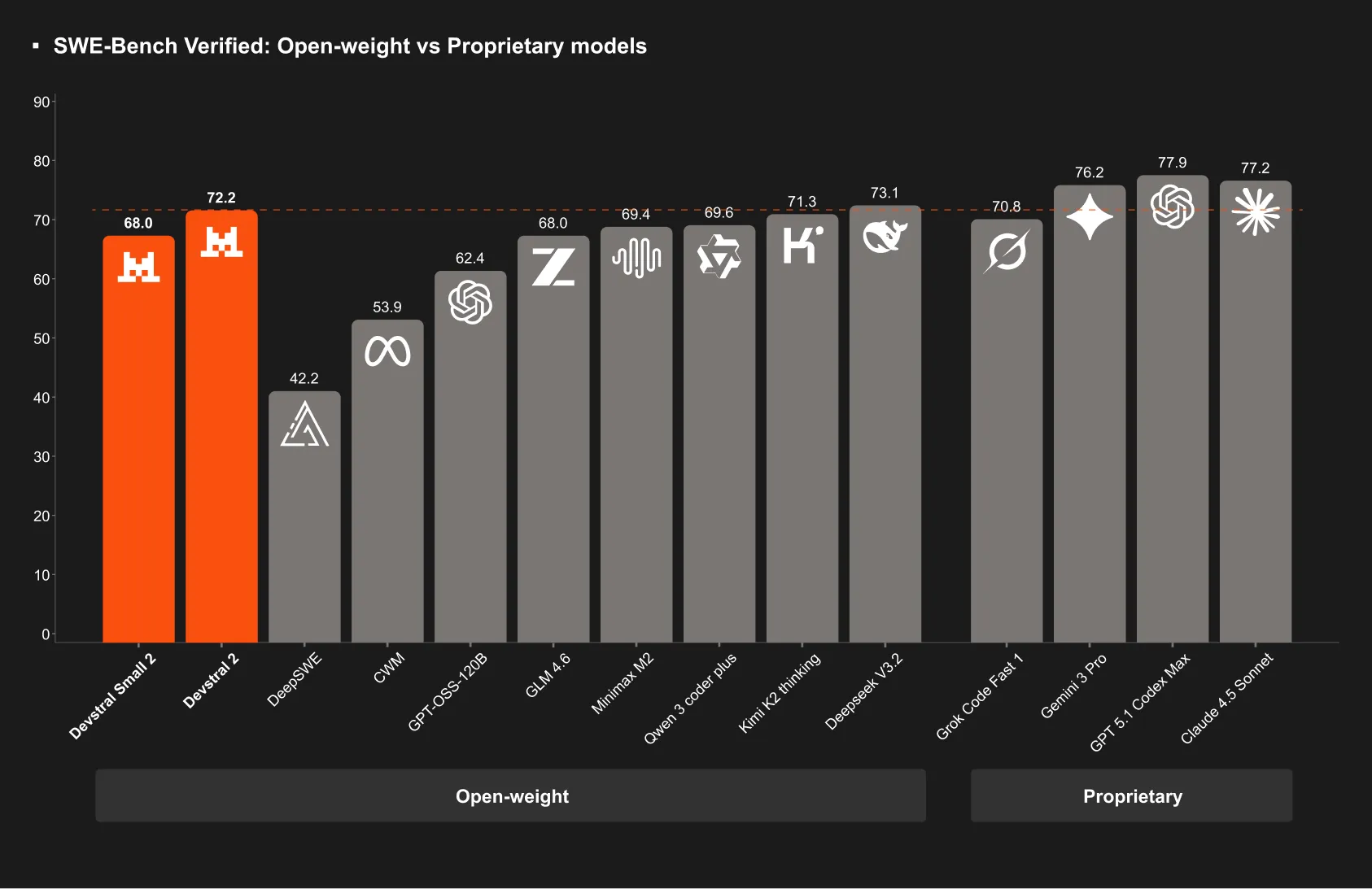

Mistral AI has released its new coding LLM Devstral 2 in two sizes. The flagship model has 123 billion parameters. The compact version, Devstral 2 Small, has 24 billion parameters.
Devstral 2 is a transformer model with a context length of 256,000 tokens and achieves 72.2 percent on SWE bench Verified. This sets new standards for coding agents in the area of open weights, especially when cost efficiency is taken into account. Devstral 2 Small achieves 68.0 percent on the same metric, placing it in the performance class of models that are significantly larger.
Not only are the benchmarks important to me, but also the license terms. Devstral 2 is distributed under a modified MIT license. Devstral 2 Small is distributed under Apache 2.0. The modified MIT license contains restrictions for very large companies, which can have practical implications for commercial use. Anyone who wants to use the models in larger companies should carefully review the license.
Mistral also emphasizes that Devstral 2 and Devstral 2 Small are significantly smaller than some competing models. The reduced model size makes them practical for use on limited hardware and lowers the barrier to entry for developers, small companies, and hobbyists. This is an important argument for those who want to run models locally or control costs.
I have already tested Devstral 2 Small on my MacBook. Subjectively, the results are comparable to Qwen 3 Coder. Devstral 2 Small requires slightly less RAM than Qwen 3 Coder. However, in terms of speed, the models are far apart. Devstral 2 Small generates about 14 tokens per second. Qwen 3 Coder 30B achieves approximately 56 tokens per second thanks to its MoE technology. Since I consider the output quality of both models to be equivalent, I will stick with Qwen 3 Coder 30B for the time being. This practical experience is often the most important decision criterion alongside benchmarks and licensing issues.
Even though I am not currently betting on Devstral 2 from Mistral in France, I am still glad that we have Mistral AI, a European provider that produces competitive LLMs.



{kind=link}