ACE Step 1.5 XL
When Local Music AI Comes of Age
A collection of 4 Posts
When Local Music AI Comes of Age
ACE-Step 1.5 is a new open-source text-to-audio model licensed under MIT. It achieves quality on par with proprietary models (between Suno v4.5 and v5) and generates complete songs extremely quickly (under 10 seconds per song on an RTX 3090). The model runs locally, for example, without any problems on a MacBook, so there is no cloud dependency.
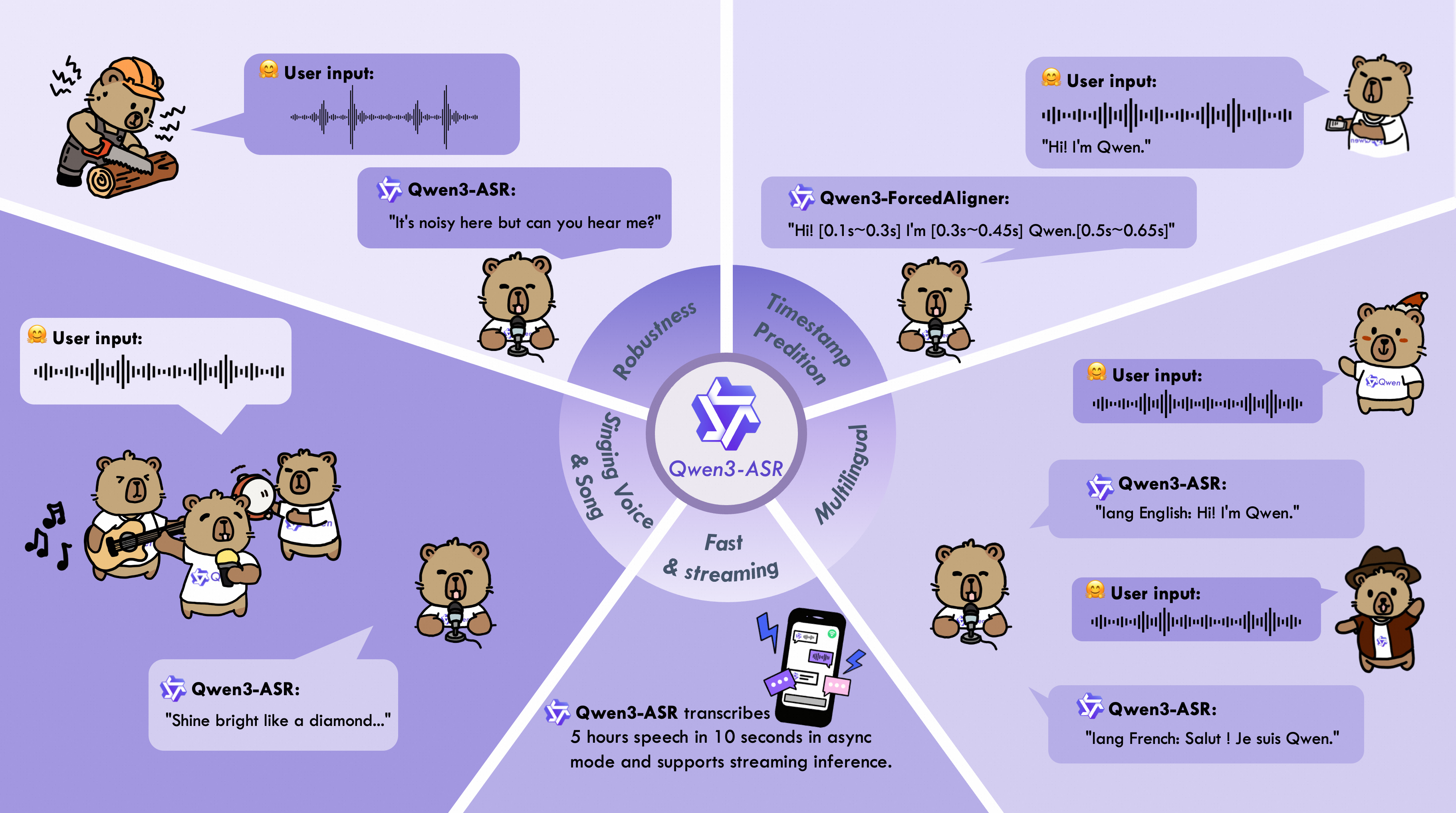
Whisper has long been my favorite open-source speech recognition model, as no other model was comparably reliable in everyday use. However, Alibaba has now introduced a very convincing alternative in the form of Qwen3-ASR. The models (1.7B and 0.6B) support over 50 languages, deliver very high recognition accuracy—even with background noise—and run efficiently on standard hardware. Thanks to its Apache 2.0 license and strong practical results, Qwen3-ASR is a serious new competitor for Whisper.
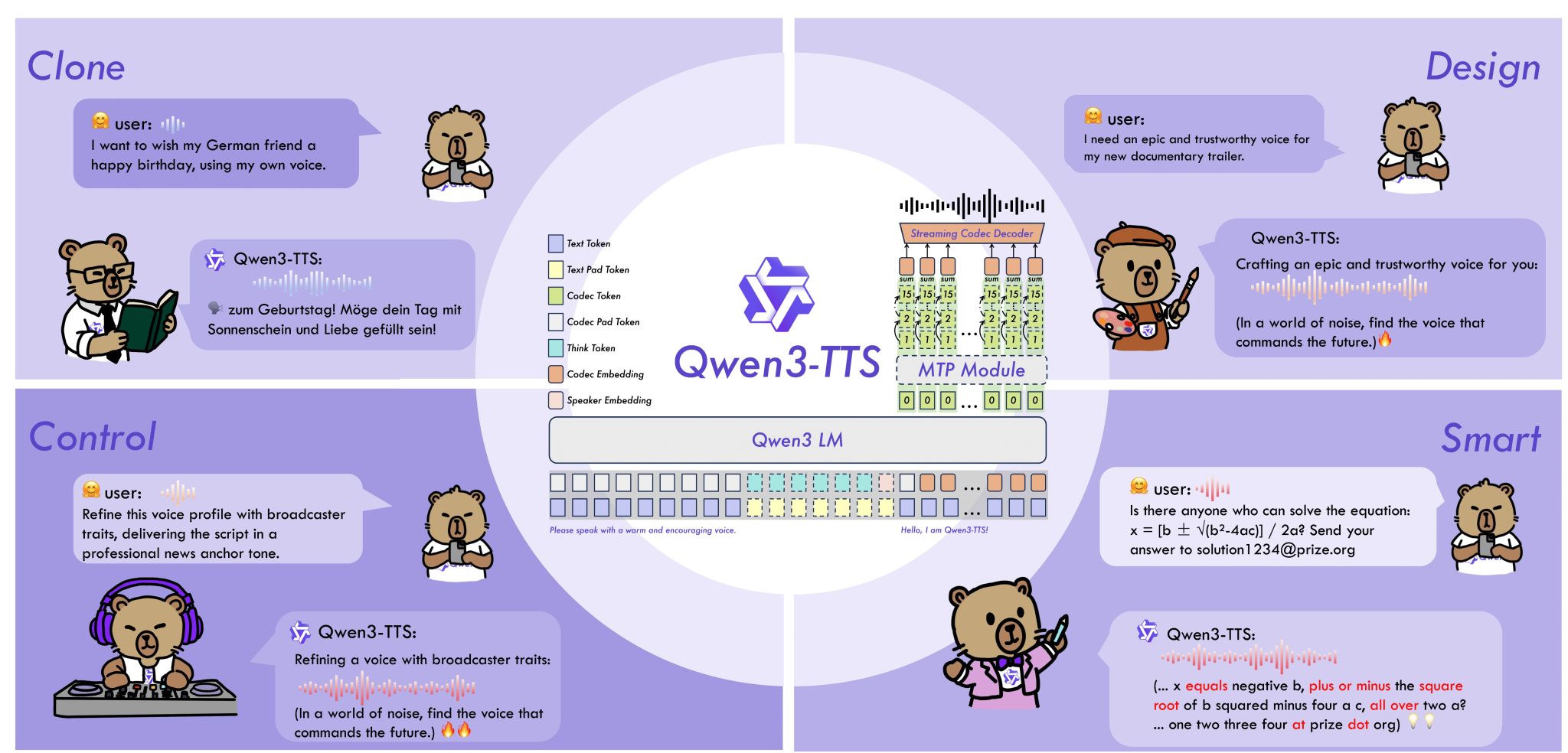
New text-to-speech model by Qwen changes my setup.