
GLM-4.7-Flash: Neues 30B-KI-Modell von Z.AI mit beeindruckender Agenten-Performance
Modell & Lizenz: GLM-4.7-Flash ist ein 30B-Parameter Mixture-of-Experts (MoE)-Modell (ca. 31B gesamt, 3B aktiv). Es ist Open-Source (MIT-Lizenz) und damit unternehmensfreundlich verfügbar.
Einsatzbereiche: Z.AI bewirbt GLM-4.7-Flash als “best-in-class” für Programmierung, agentische Workflows und Chat. Das Modell unterstützt extrem lange Kontexte (~200.000 Token) und kann mit ~24 GB (4-bit quantisiert) auf aktuellen High-End-Laptops oder Workstations laufen.
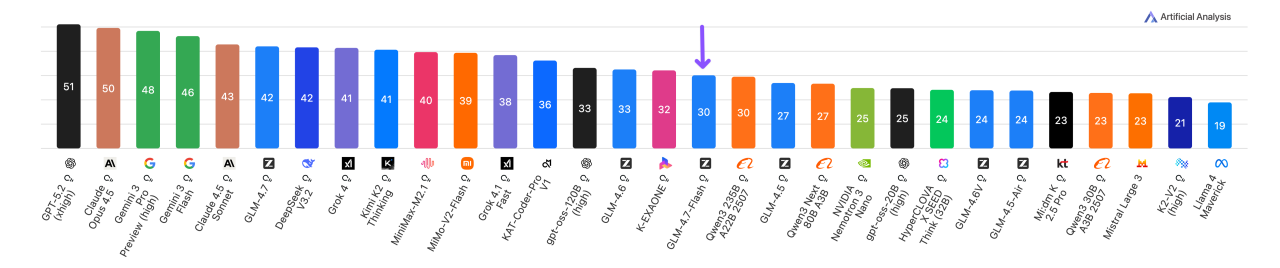
Benchmarks: Trotz seiner moderaten Größe erzielt GLM-4.7-Flash außergewöhnliche Benchmarkergebnisse. Auf spezialisierten Tests liegt es weltweit an der Spitze aller Open-Weights-Modelle unter 100B. In der jüngsten „Artificial Analysis Intelligence Index“-Evaluation erreicht es den Höchstwert für agentische Intelligenz (Intelligence Index 30). So erzielt es etwa rund 99 % auf dem τ²-Bench-Telekom-Test (höchster Wert aller verglichenen Modelle). Auch auf dem SWE-Bench (Programmieren) liegt es mit ~59,2 % deutlich vor anderen 20–30B-Modellen.
Stärken – Agentic & Effizienz: Besonders beeindruckend sind die agentischen Fähigkeiten. GLM-4.7-Flash erreicht einen ELO-Wert von 887 auf dem GDPval-AA (realistische Wissensarbeits-Aufgaben) und einen Agentic Index von 46 – jeweils Spitzenwerte für Modelle unter 100B. Mit seiner MoE-Architektur liefert es damit einen Großteil der Performance des viel größeren GLM-4.7 (355B) bei nur einem Bruchteil der Rechenkosten. In der Praxis nutze ich das Modell als lokalen Coding-Agent (z.B. OpenCode) und als allgemeinen Assistent (OpenClaw) – beides Open-Source-Tools, die sich nahtlos anbinden lassen.
Schwächen – Wissensdomain: Wie erwartet zeigt GLM-4.7-Flash vergleichsweise geringe Leistung bei reinen Wissensaufgaben. Im Omniscience-Index der Analyse liegt es mit −60 weit hinter Konkurrenzmodellen (critically) und erreicht etwa 0,3 % auf dem CritPt-Frontier-Test. Kurzum: Für neuestes Hintergrundwissen oder exaktes Faktenwissen ist es weniger geeignet.
Einsatz und Erfahrungen: Ich habe GLM-4.7-Flash lokal ausprobiert, indem ich die 4-Bit-quantisierte Version von Unsloth heruntergeladen habe (ca. 17 GB GGUF-Modelldatei). Auf meinem MacBook (M2/M3 Pro mit 32 GB Unified Memory) lässt sich das Modell problemlos starten – sogar in 4-Bit mit llama.cpp. In Kombination mit OpenCode arbeitet es zuverlässig als Programmier-Assistent: Man beschreibt eine Aufgabe, und OpenCode plant und generiert Quellcode automatisiert. Auch OpenClaw (ein Open-Source-Agent) koppelt sich gut an den lokalen Server an und kann komplexere Agenten-Workflows steuern.
Limits: In der Praxis läuft GLM-4.7-Flash sehr flüssig für kleine bis mittelgroße Aufgaben. Bei extrem komplexen Multi-Step-Problemen oder sehr langen Sessions kann jedoch der Kontext füllen und die Agenten-Ausführung ab und zu abbrechen. Hier ist dann ein Neustart der Sitzung oder eine manuelle Zwischenerklärung nötig.
Abschließend lässt sich sagen: GLM-4.7-Flash vereint eine leichte Deploybarkeit (24–32 GB RAM), hohe Effizienz und herausragende agentische Fähigkeiten. Für Entwickler ist es derzeit das stärkste frei verfügbare Modell unter 100B (mit MIT-Lizenz). Weitere Details und technische Infos findet man in der Unsloth-Dokumentation, auf Hugging Face sowie im Deep-Dive-Artikel von Artificial Analysis.
./llama-server \
--model unsloth/GLM-4.7-Flash-GGUF/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "unsloth/GLM-4.7-Flash" \
--fit on \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--ctx-size 16384 \
--port 8001 \
--jinja
llama-server.exe \
--model unsloth/GLM-4.7-Flash-GGUF/GLM-4.7-Flash-UD-Q4_K_XL.gguf \
--alias "unsloth/GLM-4.7-Flash" \
--fit on \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--ctx-size 16384 \
--port 8001 \
--jinja


{kind=link}