
When it comes to speech recognition, OpenAI’s Whisper has long been my favorite. Whisper is a freely available ASR (Automatic Speech Recognition) encoder that has been trained on 680,000 hours of multilingual audio-text training. Whisper is based on a large and diverse dataset, which makes it particularly robust against accents, background noise, and technical language. In practice, Whisper produced very reliable transcriptions. I have also tried other open-source models in recent years (e.g., NVIDIA Parakeet and Canary or Mistral’s Voxtral), but in practical use, none of them have been able to match the reliability of Whisper.
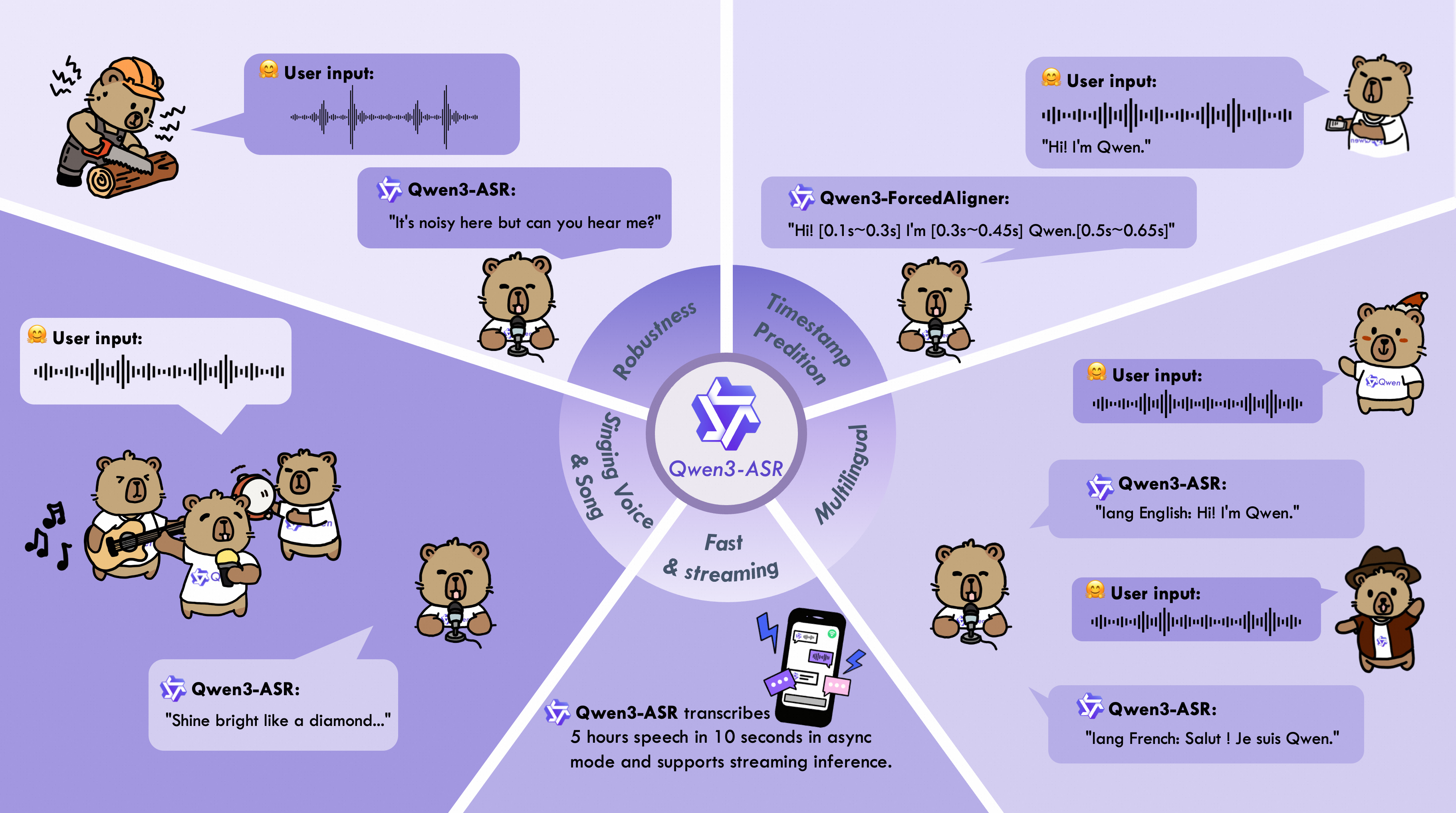
Now, the Qwen team (Alibaba) has introduced the new Qwen3 ASR model, which looks really promising at first glance. According to the developers, the Qwen3-ASR family includes two variants (a large 1.7B model and a small 0.6B model) that support speech and speech recognition in 52 languages and dialects. This model is based on their large Foundation Model Qwen3-Omni and uses huge training data to enable particularly robust recognition.
The most important features are:
- Supports over 50 languages and dialects.
- Extremely high recognition accuracy (state-of-the-art in the open source sector).
- Two variants: 1.7B (highest accuracy) and 0.6B (extreme efficiency).
- Released under Apache 2.0 license (open source).
The 1.7B version achieves peak performance and is designed to compete with even the most powerful commercial ASR APIs. The smaller 0.6B version is highly optimized for efficiency. It offers extremely high throughput. Tests have also shown that Qwen3-ASR works very accurately even in noisy or complex environments.
In my tests, Qwen3-ASR actually makes a very good impression. The transcriptions were amazingly accurate, both with clear speech inputs and slightly noisy speech. Both models are very lightweight and run smoothly even on consumer hardware (MacBook, Raspberry Pi, etc.). Its Apache 2.0 license also makes the models interesting for commercial use.
import torch
from qwen_asr import Qwen3ASRModel
device = "cpu"
if torch.backends.mps.is_available():
device = "mps"
if torch.cuda.is_available():
device = "cuda:0"
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map=device,
max_inference_batch_size=-1,
max_new_tokens=4096,
)
results = model.transcribe(
audio="test.wav", # <- base64 Unterstützung
language=None,
)
print(results[0].language)
print(results[0].text)



{kind=link}