
Just a few weeks ago, I was still celebrating the Qwen-3.5-Medium series. And now Google has introduced the new Gemma 4. According to Google, it is the most intelligent open model family the company has released so far. Officially, Gemma 4 comes in four sizes: E2B, E4B, 26B A4B, and 31B. It also offers up to a 256K context window, native support for more than 140 languages, and an Apache 2.0 license.
Google has structured the family in a sensible way. E2B and E4B are clearly intended for edge, mobile, and IoT scenarios, while 26B A4B and 31B target PCs, workstations, and local developer setups. The model card specifies 128K context for the smaller models and 256K for the larger ones. On top of that, there are multimodal capabilities, a thinking mode, and native function-calling support. Exactly the combination that makes local, agent-based workflows interesting.
For me, the 26B A4B is currently the sweet spot. Officially, it’s a mixture-of-experts model with nearly 26 billion total parameters, but only about 4 billion active parameters per inference. And you can really feel that. All sizes run on my MacBook, but the 26B A4B is the perfect balance of size and performance for me.
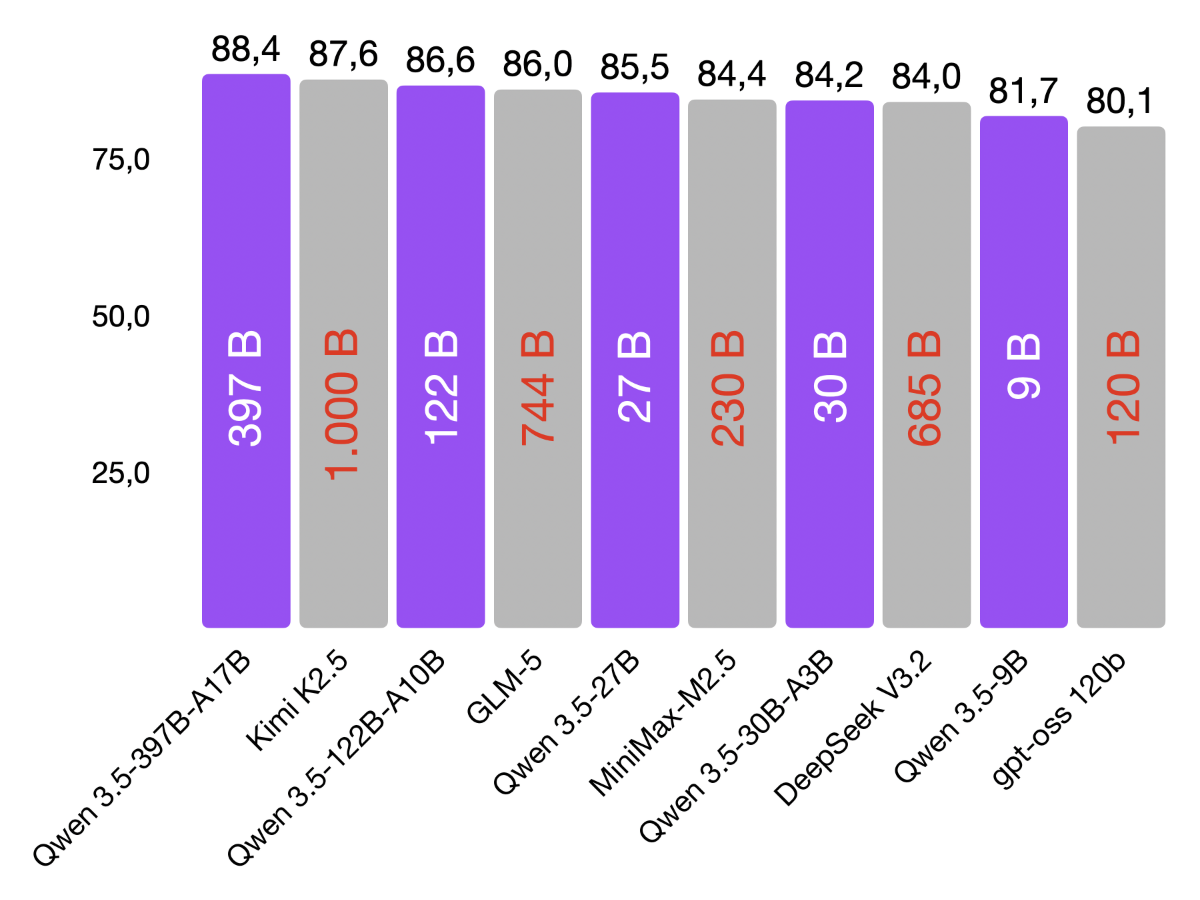
The official benchmarks also read quite aggressively. The 26B A4B scores 77.1 on LiveCodeBench v6 and 82.3 on GPQA Diamond in Google’s model card, while the 31B goes even higher with 80.0 and 84.3 respectively. My first coding tests on the MacBook were accordingly fantastic. I can easily achieve around 30 tokens per second with the 26B A4B.
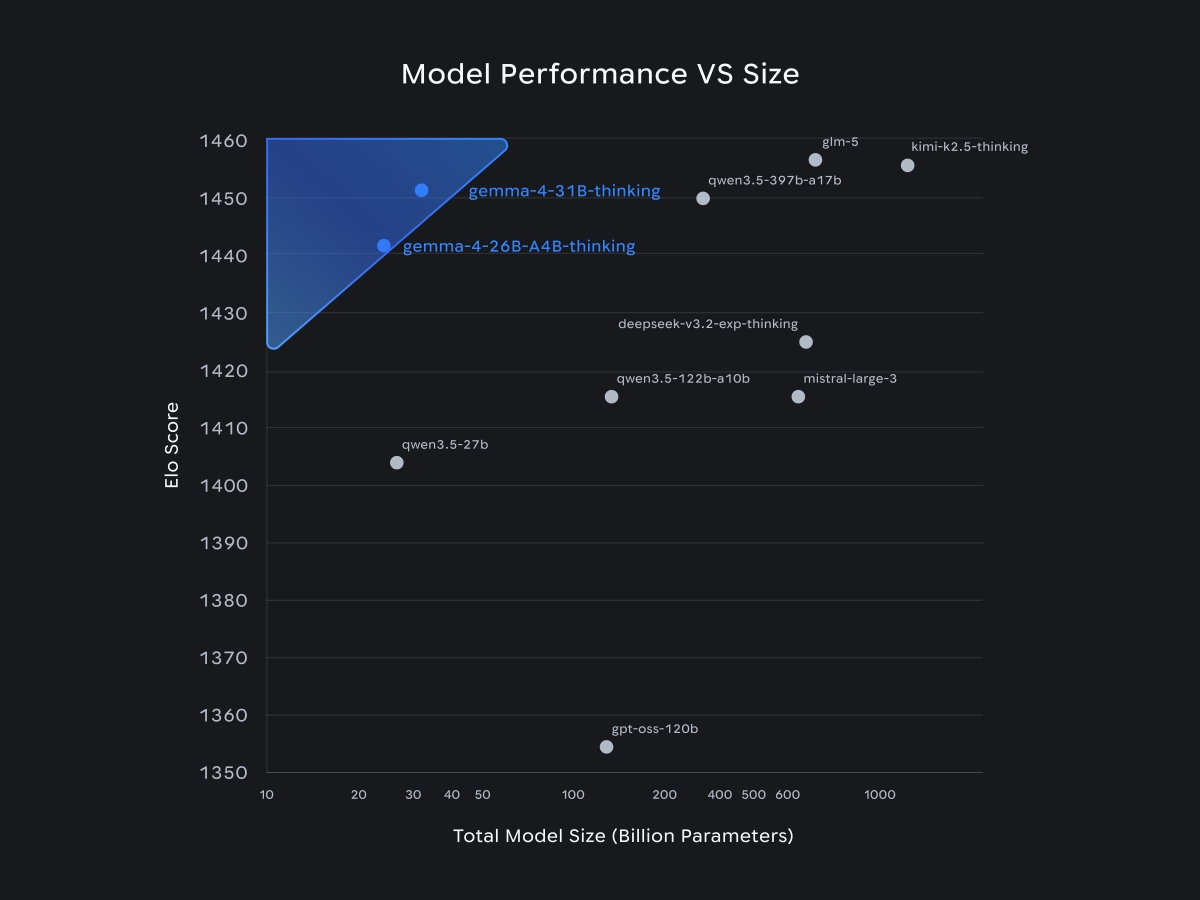
I’m deliberately saying this as an initial impression, not a final verdict. Just a few days ago, the Qwen-3.5-Medium series was the benchmark for me. After the first few hours with Gemma 4, that suddenly feels different. At least on the current Arena text leaderboard, Gemma 4 31B is ahead with a score of 1452, compared to Qwen3.5-27B with 1404 and Qwen3.5-35B-A3B with 1400. Even the 26B A4B reaches 1441 there.
What I find particularly exciting about Gemma 4 is the combination of performance, licensing, and ecosystem. Apache 2.0 is a huge advantage for local products, fine-tuning, and secure deployments. On top of that, there’s day-one support in tools like Hugging Face, Ollama, LM Studio, and MLX. To me, this is what modern on-device AI looks like: local, fast, multilingual, multimodal—and without licensing headaches.
I’ll use the long Easter weekend to continue testing the Gemma 4 models—especially in day-to-day coding, with long contexts, and in real local workflows. I’ll keep you posted.


{kind=link}