

Standardized AI benchmarks such as MMLU, HumanEval, or SWE-bench measure the factual and programming knowledge of models. However, they do not test whether an AI can make many small decisions in sequence. This is exactly where FoodTruck Bench comes in. In this simulation, language models are given a virtual food truck startup in Austin, Texas. Over 30 days, they must choose locations, design menus, set prices, manage inventory, hire staff, and even take out loans—simultaneously. Every decision creates the starting conditions for the next day. Mistakes like missing orders or incorrect pricing have immediate consequences. This kind of cognitive load cannot be captured in multiple-choice tests.
FoodTruck Bench is a mix of business simulation and benchmark. Each model receives the same starting conditions: $2,000 in capital, one food truck, and 30 days. The simulation provides 34 different tools that the AI uses to retrieve information and make decisions—from weather reports and customer reviews to inventory and financial data. The tools are called in JSON format. After each round, the AI processes the results, analyzes them, and plans the next day. What matters is not a single perfect step, but 30 days of interdependent decisions.
Through this design, the benchmark tests the agentic capabilities of AI models under uncertainty. It also allows humans to compete with the models. Anyone can run the same food truck with the same tools and see how they perform in comparison. For on-device AI enthusiasts like me, this is particularly exciting, as it shows whether smaller, locally runnable models can compete with large proprietary systems.
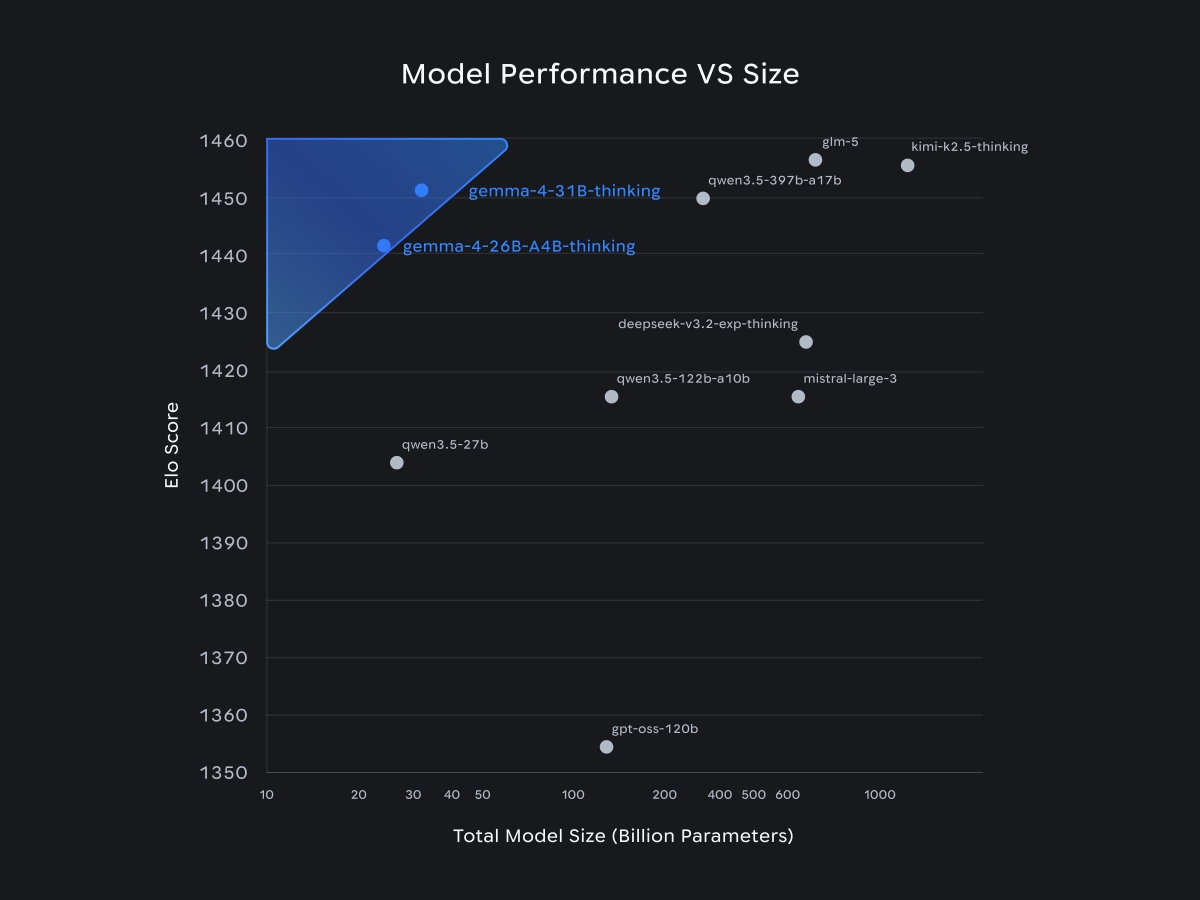
The current leaderboard clearly shows how differently models handle the food truck scenario. Claude Opus 4.6 leads with a final net worth of $49,519 and an impressive return of +2,376%. It is followed by GPT-5.2 with $28,081 and +1,304% ROI. Gemma 4 31B, an on-device AI model, ranks third with $24,878 and +1,144% ROI. Behind it are Claude Sonnet 4.6 and Gemini 3 Pro.
All other open-weights models (including significantly larger ones) go bankrupt before the 30 days are over. GLM 5, Qwen 3.5 397B, DeepSeek V3.2, and Kimi K2.5 all fail in the simulation. In contrast, Gemma 4 31B runs the business profitably throughout. The difference becomes even clearer when comparing cost per run: according to the case study, Gemma 4 requires only $0.20 per run while still delivering stable returns. Gemini 3 Pro costs $2.95—15 times as much—Sonnet 4.6 costs $7.90, and GPT-5.2 about $4.43 per run.
The FoodTruck Bench case study on Gemma 4 provides further details. In all five simulations, the model survived the full 30 days without bankruptcy, loan defaults, or downtime. In four out of five runs, it purchased all eight available upgrades for kitchen, storage, and marketing, investing $5,150 strategically into the future. Returns ranged from +457% to +1,354%. Even the worst run would have outperformed models like Gemini 3.1 Pro and Qwen 3.5 397B. Gemma 4 does not use a special function-calling interface but instead calls all 34 tools via text while strictly adhering to the JSON schema—resulting in zero parsing errors and up to 488 tool calls per run.
Gemma 4 demonstrates that a locally runnable 31B model can be not only efficient but also highly capable in agentic tasks. While other open-weight models fail in the benchmark, Gemma 4 keeps the business profitable for the full 30 days. This opens up new possibilities for edge-based business intelligence or local automation without reliance on cloud APIs.
FoodTruck Bench evaluates not only profit but also API costs. According to the analysis, Gemma 4 generates around $124,000 in simulated net value per dollar spent on API usage. GPT-5.2 achieves only $3,100, and Sonnet 4.6 about $2,200. This makes Gemma 4 roughly 40–56 times more cost-efficient. For on-device applications, where compute and budgets are limited, this efficiency matters even more.
I like FoodTruck Bench because it is practical and fills an important gap. It forces models to make many interconnected decisions and deal with their consequences over time. In my own projects on mobile devices or small workstations, I encounter exactly this challenge: reading sensor data, making decisions, and managing resources—all without constant cloud connectivity. Gemma 4 proves that a well-trained model can handle this environment, while more cumbersome models fail.
FoodTruck Bench is more than just a game. It is a comprehensive test for agentic AI. It demonstrates that knowledge alone is not enough—decision-making ability, flexibility, and cost awareness are equally important. In this benchmark, Gemma 4 shows that on-device AI models can not only keep up but even compete with proprietary frontier models. For developers, this means that choosing local models does not necessarily require sacrificing performance. Gemma 4 is a strong example of the potential unlocked by combining open weights with efficient architectures.

{kind=link}