
There are only rare moments when a new model immediately makes me feel that something fundamental is shifting. With ACE Step 1.5 XL, I had exactly that feeling. In early April 2026, the XL series was released and the new variants were made available on Hugging Face under the MIT license. The XL variants are larger than the previous 2B models and are explicitly aimed at higher audio quality without losing sight of local deployment. For me, that is the decisive point. It is not just about demo quality, but about real usability.
What makes ACE Step 1.5 XL so special
The model can generate music from text, derive cover versions from existing audio, selectively recalculate sections of a piece, extract individual stems, and directly control metadata such as duration, BPM, key, and time signature. On top of that, it supports more than 50 languages and spans everything from short loops to compositions of up to ten minutes. For local AI, that is a remarkable combination of control, range, and speed.
ACE Step 1.5 XL comes in 3 variants. The Base version is the broad foundation for all tasks. The SFT version focuses on the highest quality and finer prompt adherence. The Turbo version compresses the process into just eight inference steps, combining speed and quality in a way that is enormously valuable for local workflows.
There is also one point that matters far more in day-to-day use than many people think: legal usability. According to the official model descriptions, ACE Step 1.5 XL was trained on legally compliant datasets. The maintainers provide the models under the MIT license and explicitly position the generated music as commercially usable. For creatives, agencies, studios, and product teams, that is not just a nice bonus, but often the prerequisite for turning technical curiosity into a real workflow.
My personal experience
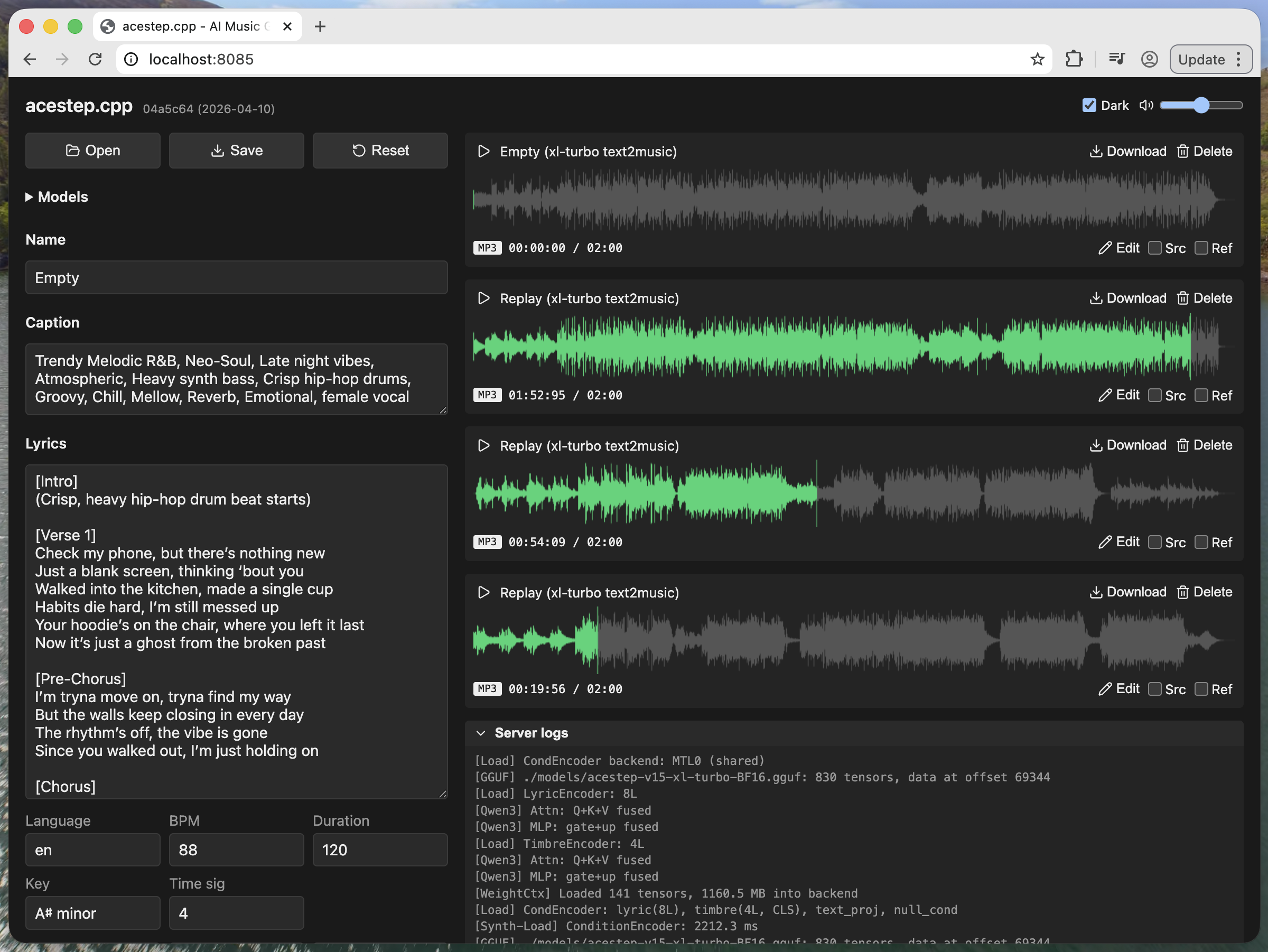
I use the acestep.cpp library for generation. The model runs without any issues on my MacBook, and to me the quality feels on a level I would otherwise associate more with Suno. The “small” ACE Step 1.5 model can run very efficiently, even with less than 4 GB of VRAM. But different standards apply to the XL models. Using acestep.cpp, the XL Turbo model requires around 11 GB of VRAM on my MacBook. Thanks to the Turbo variant and its 8 steps, generation is completed in just a few seconds.
Style control
As with Suno, the style is described through text. For example: pop, uplifting, piano, warm, 80s synth-pop, studio-polished, female vocal, breathy, mid-tempo, fade-out ending.
The lyrics are added with tags such as [Intro], [Verse], [Chorus], [Outro], …
Then you only need to specify the tempo (BPM), the key (for example A♯ minor), language, and duration, and press “Synthesize.” After a few seconds, you have a song as an MP3 file.
Scope of application
ACE Step 1.5 XL is not only interesting for music producers. For film, games, marketing, and digital products, a model like this opens up a new form of tailored sound design. Instead of relying on generic libraries, teams can tie music much more closely to narrative, brand, scene, or interaction.
My outlook
For me, ACE Step 1.5 XL is the most exciting on-device AI music model of its time. I am thrilled by the quality and generation speed on my MacBook. Through the acestep.cpp library, we will likely see quite a few integrations into software products. The MIT license makes that easy. I will continue using it to generate feel-good music for myself.


{kind=link}