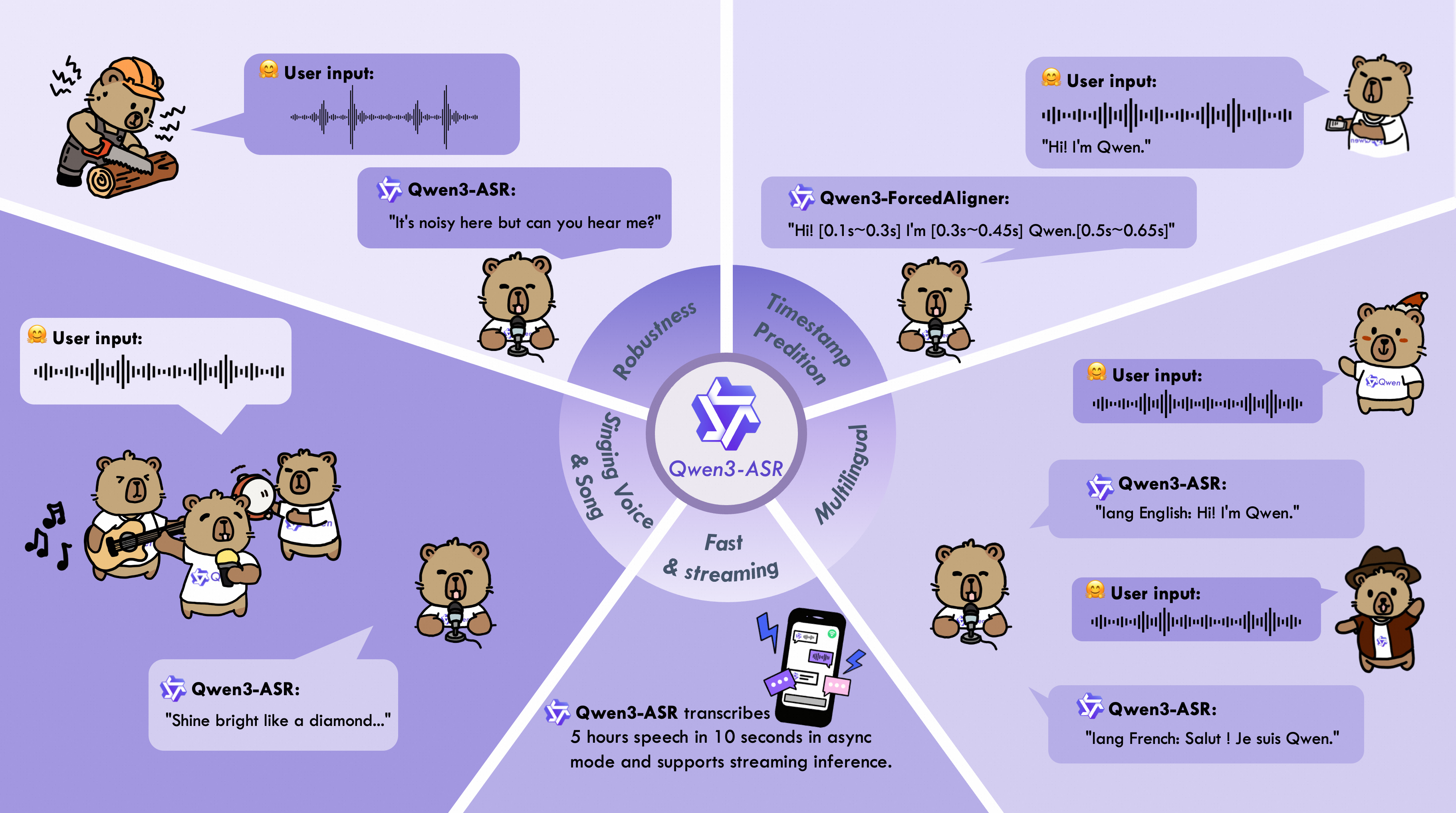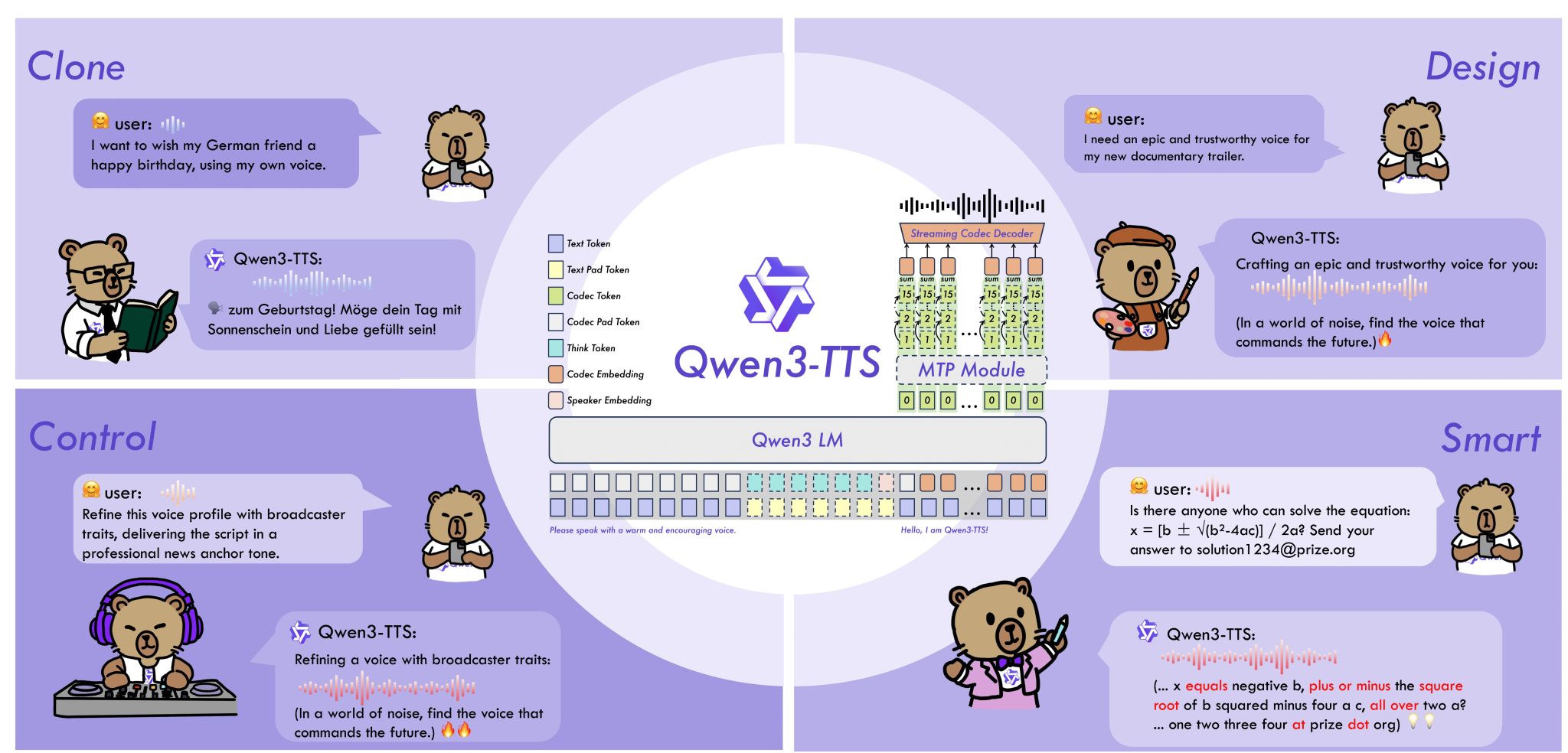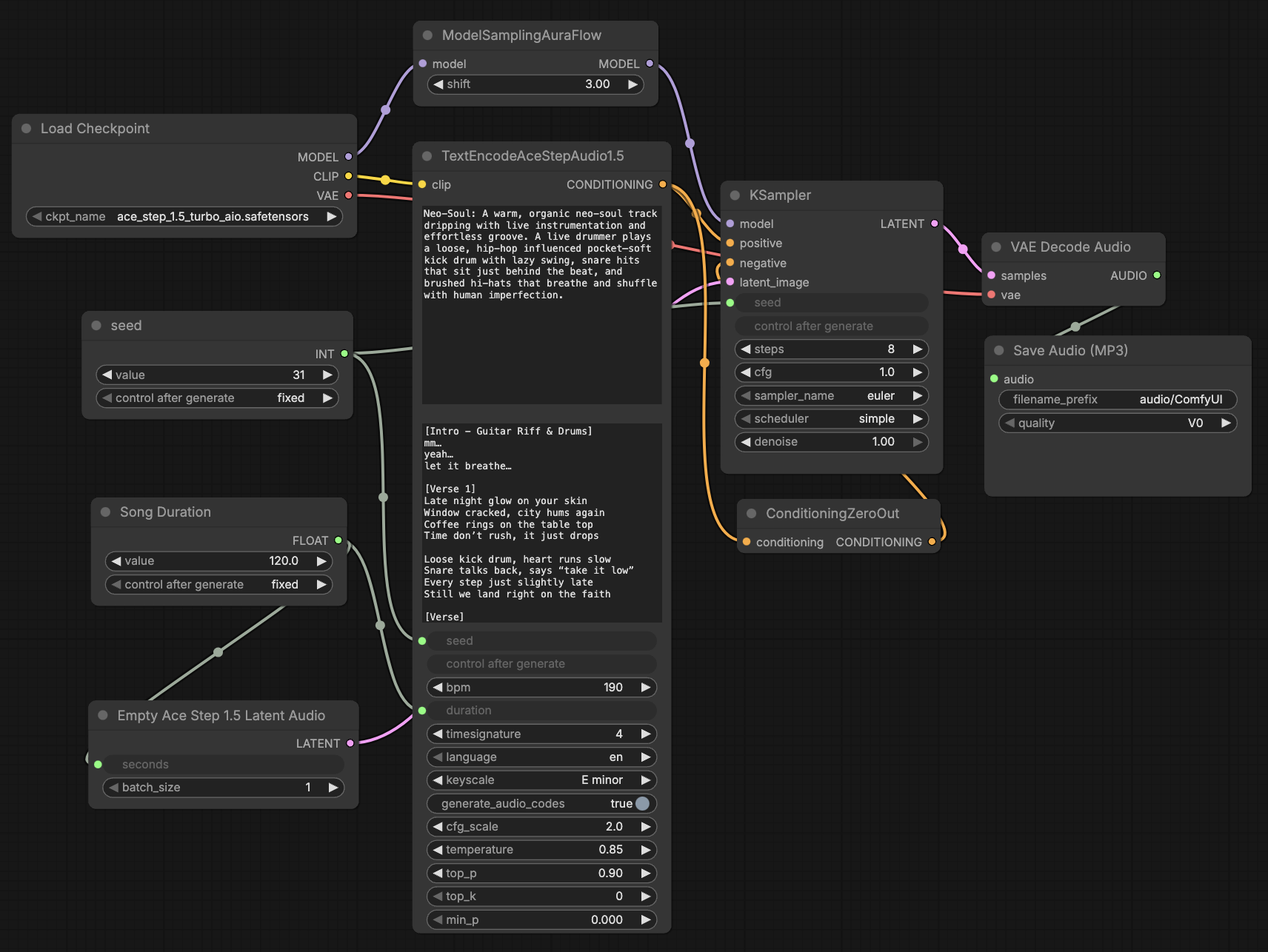
ACE-Step 1.5: New Text-to-Audio Model
ACE-Step 1.5 is a new open-source text-to-audio model licensed under MIT. It achieves quality on par with proprietary models (between Suno v4.5 and v5) and generates complete songs extremely quickly (under 10 seconds per song on an RTX 3090). The model runs locally, for example, without any problems on a MacBook, so there is no cloud dependency.